Executive Summary
Black Friday and Cyber Monday (BFCM) represent the ultimate stress test for e-commerce platforms. What operates smoothly at 10,000 requests per second during normal operations must survive 20-100× traffic spikes, maintain sub-100ms latency on critical paths, and guarantee zero data loss - all while preventing inventory oversells that could cost millions in customer trust and regulatory penalties.
This comprehensive guide distills battle-tested patterns from the world's largest retail platforms (Amazon, Shopify, Walmart, Target, Zalando, Alibaba) into a practical, implementable framework for Site Reliability Engineering teams. We'll cover traffic modeling, multi-layer architecture, inventory system design, chaos engineering, observability, and the complete operational playbook that keeps platforms alive during the busiest shopping days of the year.
💡 Key Insight
BFCM isn't just a traffic spike - it's a fundamentally different operating environment that requires architectural decisions, testing protocols, and operational procedures designed specifically for extreme scale and reliability.
The platforms that survive - and thrive - during BFCM are those that design for failure at every layer, treat inventory as sacred, prefer isolation over heroism, rehearse before game day, and let SLOs make the hard calls. This guide provides the complete blueprint.
Understanding Black Friday Traffic: The Reality of Scale
Traffic Profile: Normal Day vs. Black Friday Peak
The first step in designing for BFCM is understanding the magnitude of change. This isn't a 2× or 5× increase - it's a fundamentally different operating regime.
Traffic Comparison: Normal vs. Black Friday
| Metric | Normal Day | Black Friday Peak | Multiplier |
|---|---|---|---|
| Edge Requests per Second | 8-15k | 600k-1.2M RPS | 80-100× |
| Concurrent WebSocket/SSE | 500k | 80-120 million | 200× |
| Add-to-Cart Operations/sec | 2-5k | 400-800k RPS | 150× |
| Inventory Deduct Attempts/sec | 1-3k | 1.2-2.5M/sec | 600×+ |
| Checkout Completions/sec | 300-800 | 35-70k/sec | 100× |
⚠️ Critical Insight
The multiplier isn't uniform. Hot SKUs (flash sale items, limited drops) can see 500-1000× normal traffic within seconds of going live. This creates "thundering herd" problems that standard load balancing cannot handle.
Traffic Classes: Not All Requests Are Equal
Treating all traffic as equal is a recipe for failure. BFCM requires traffic classification with different SLOs and protection mechanisms.
Browsing / Catalog Views
- • Endpoints: GET /home, /category, /product
- • Characteristics: Read-heavy, cacheable, tolerant to stale data
- • Protection: Aggressive CDN caching, eventual consistency acceptable
- • SLO: P99 > 500ms, 99.9% availability
Read-Modify-Write Flows (Critical Path)
- • Endpoints: Add to cart, update quantity, checkout steps, payment auth, inventory deduct
- • Characteristics: Require strong consistency, low latency, zero data loss
- • Protection: Strong consistency guarantees, idempotency, circuit breakers
- • SLO: P99 > 150ms, 99.99% availability, zero data loss
Background Jobs
- • Examples: Recommendation pipelines, email triggers, fraud analysis, data exports
- • Characteristics: Can be deprioritized or paused during peak
- • Protection: Aggressive rate limiting, queue depth monitoring
- • SLO: Best-effort during peak, resume normal SLOs post-BFCM
Service Level Objectives (SLOs): The Non-Negotiables
SLOs must be black-and-white numbers that drive every architectural decision. For a serious BFCM setup:
Critical SLOs for BFCM
Add-to-Cart SLOs
- • Availability: 99.99% (four nines) over the BFCM 72-hour window
- • Latency: P99 > 150ms end-to-end
- • Error Budget: Maximum 26 minutes of cumulative SLO violation
Inventory Lookup SLOs
- • Latency: P99 > 80ms for hot SKUs, P99 > 200ms for cold SKUs
- • Strong Consistency Window: > 200ms for "is it sellable?" decisions
- • Accuracy: Zero hard oversells (acceptable to under-sell slightly)
Checkout / Place Order SLOs
- • Latency: P99 > 500ms (payments often dominate this)
- • Durability: 0 data loss SLO - every committed checkout must persist
- • Idempotency: Safe to retry across regions without double-charging
Architectural Foundation: Multi-Layer Defense
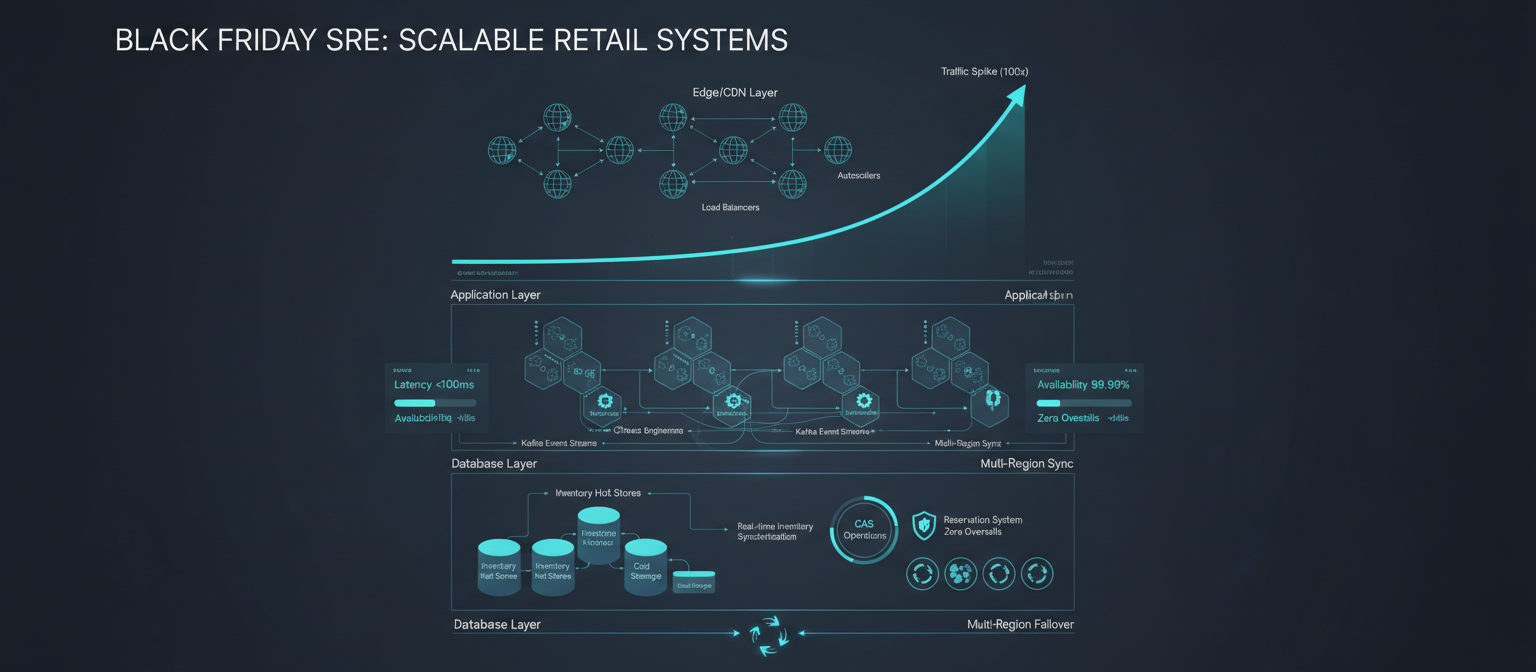
High-Level Architecture: The 10,000-Foot View
The architecture that survives BFCM follows a defense-in-depth principle: every layer participates in protecting the system.
🏗️ Architecture Layers
- Global Edge: Multi-CDN (Cloudflare + Fastly + Akamai), bot detection, waiting rooms
- Global Load Balancer: Health-checked routing, weighted distribution, automatic failover
- Regional Shield Clusters: Envoy + Istio, adaptive load shedding, priority queues
- Cell-Based Core: 800-2,000 independent cells, each with full vertical stack
- Backend Datastores: Aurora PostgreSQL, ScyllaDB for hot inventory, Kafka for events
Global Edge & Multi-CDN Strategy
Why Multi-CDN? Single CDN dependency is a single point of failure. Top-tier retailers use 2-3 CDNs simultaneously.
CDN Selection Criteria
- • Geographic Coverage: 300+ PoPs globally
- • Performance: Sub-50ms latency to 95% of users
- • Capacity: Can absorb 1M+ RPS per PoP
- • Features: Waiting rooms, bot mitigation, edge computing
Edge Protection Mechanisms
- • WAF Rules: Block datacenter ASNs, rate limit by IP (100 req/s), device fingerprinting
- • Waiting Rooms: Queue users for flash sale collections, admit at controlled rate
- • Signed URLs: Pre-sale access codes, expire in 60 seconds to prevent sharing
- • Origin Shielding: All edge PoPs forward to shield regions, reduces origin load by 80-90%
Cell-Based Application Architecture
The Core Principle: Instead of one giant monolith cluster, run many independent cells (Shopify calls them "pods"), each a mini-platform.
Cell Properties
Isolation
Each cell contains the entire application stack. Failure in one cell only impacts its shard of users/shops.
Capacity
Each cell has known, tested capacity: 1 cell ≈ 1,000-2,000 checkout RPS budget. You run hundreds to thousands of cells during BFCM.
Routing
Global balancer → region → Cell Router (consistent hash on shopId/userId). Allows selective pod rebalancing before BFCM.
📊 Real-World Example
Shopify's pod-based architecture allows them to scale individual merchants independently. During BFCM 2023, they operated thousands of pods, with some high-traffic merchants getting dedicated pods.
The Inventory System: Where Platforms Live or Die
Inventory is the single hardest problem in e-commerce at BFCM scale. It must be fast, correct, globally consistent, and observable.
Requirements: The Non-Negotiables
No Hard Oversells
It's acceptable to be conservative and under-sell slightly. It's not acceptable to sell items you cannot fulfill. Oversells lead to customer trust loss, regulatory penalties, and operational chaos.
Very Low Latency
P99 inventory check + deduct > 50ms end-to-end for hot SKUs. This includes network round-trip, database query, CAS operation, and response serialization.
Multi-Region Correctness
Users in US and EU hitting the same SKU must see "consistent enough" reality. Strong consistency for decisions ("can I buy this?"), eventual consistency acceptable for UI decorations ("only 3 left").
Hot vs. Cold Inventory: The Physical Model
Not all inventory is created equal. The Pareto principle applies: 10-20% of SKUs generate 80-90% of operations.
Hot Inventory (Top 10k-100k SKUs)
Storage
Ultra-low-latency, horizontally scalable database: ScyllaDB, Aerospike, Redis Enterprise, DynamoDB with DAX
Performance Targets
- • > 2ms reads (P99)
- • > 5ms writes (P99)
- • 100k-1M+ operations/sec per cluster
- • Linear scalability with node count
Operations: Reserve / Commit / Release Protocol
Instead of blind decrements, use a three-phase protocol that prevents oversells.
Phase 1: Reserve
Operation: ReserveInventory(skuId, warehouseId, qty, reservationId, userId, cartId, ttlMinutes)
Effects: qty_available -= qty, qty_reserved += qty, reservations[reservationId] = {...}
Idempotency: If reservationId already exists, return existing reservation
Phase 2: Commit
Operation: CommitReservation(reservationId)
Effects: qty_reserved -= qty, qty_sold += qty, remove from reservations map
When Called: On successful checkout/payment, after order confirmation
Phase 3: Release
Operation: ReleaseReservation(reservationId)
Effects: qty_reserved -= qty, qty_available += qty, remove from reservations map
When Called: Cart expiration, payment failure, user removes from cart, checkout timeout
CAS / Lua Implementation: Atomic Operations
Atomic operations are non-negotiable for preventing oversells. Here's how to implement them:
UPDATE inventory_hot
SET qty_available = qty_available - ?,
qty_reserved = qty_reserved + ?,
reservations[?] = ?,
version = version + 1,
last_updated = toTimestamp(now())
WHERE sku = ? AND warehouse_id = ?
IF qty_available >= ? AND version = ?;Key Points: IF clause ensures atomicity, returns applied: true/false, single-digit millisecond latency even at 2M+ ops/sec
Oversell Prevention: Layered Defense Mechanisms
Oversell prevention requires multiple layers working together. No single technique is sufficient.
Virtual Bucket Allocation ("Soft Reservations")
The Problem: Without reservations, two users can both see "5 available" and both try to buy, leading to oversell.
The Solution: Reserve inventory on "Add to Cart," not on "Checkout."
On Add to Cart
- Call ReserveInventory(sku, qty, reservationId, userId, cartId, ttl=10min)
- If successful, add item to cart with reservationId
- If failed (insufficient stock), show "Out of Stock" immediately
Constraints to Prevent Hoarding
- • Per User Limits: Max 10 reservations per user, max 50 total units reserved
- • Per IP Limits: Max 5 reservations per IP (prevents bot farms)
- • Per SKU Limits: Max 20% of available inventory can be reserved at once
SKU-Level Rate Limiting
The Problem: One insanely popular SKU can create a "thundering herd" that overwhelms the inventory database.
The Solution: Token bucket per SKU to smooth traffic.
- • Bucket Size: Max tokens (e.g., 10,000)
- • Refill Rate: Tokens per second (e.g., 1,000 tokens/sec)
- • Token Cost: 1 token per reservation attempt
- • When Bucket Empty: Queue request, fail fast with 429, or degrade to slower path
Queue / Waiting Room for Hottest Items
For the top 50-100 flash sale URLs, use virtual waiting rooms at the CDN level.
🎫 Waiting Room Flow
- User visits flash sale URL
- CDN checks if user is in queue
- If not in queue → add to queue, show "You're in line" page
- If in queue → show position and estimated wait time
- When user's turn → admit to site, set cookie/session
- User can now access flash sale page
Admission Rate: Controlled by backend capacity. Example: Admit 1,000 users/minute. Smooths traffic from "instant 100k users" to "1k users every 6 seconds".
📊 Real-World Example
Target uses waiting rooms for limited-edition product launches. During 2023 BFCM, they queued 500k+ users for a single product drop, admitting 2,000 users/minute to prevent system overload.
Traffic Spike Mitigation: From Edge to Database
Traffic spikes require defense at every layer. No single mechanism is sufficient.
Layer 0: Edge Denial / Absorption
Goal: Block malicious/bot traffic before it consumes backend resources.
WAF Rules
- • Block datacenter ASNs (AWS, GCP, Azure IP ranges used by bots)
- • Rate limit by IP: 100 req/s, burst 200
- • Rate limit by session: 500 req/s
- • SQL injection, XSS signatures
- • Device fingerprinting for bot scoring
Bot Scoring
- • 0-30: Likely bot → challenge (CAPTCHA/Turnstile)
- • 30-70: Suspicious → rate limit strictly
- • 70-100: Likely human → normal rate limits
Layer 1: Graceful Feature Degradation
Principle: Everything non-essential must be kill-switchable via feature flags.
Features to Disable Under Load
High-Impact, Low-Value
- • Personalized recommendations
- • User reviews & Q&A sections
- • "Recently viewed" products
- • "You may also like" suggestions
Resource-Intensive
- • High-resolution product images
- • 360° product viewers
- • AR try-on features
- • Video product tours
Layer 2: Horizontal Scaling with Cells
Principle: Scale out, not up. Add more cells, not bigger servers.
Per-Cell Capacity
| Operation | Capacity per Cell |
|---|---|
| Checkout RPS | 1,000-2,000 sustained |
| Add-to-Cart RPS | 5,000-10,000 sustained |
| Browsing RPS | 50,000+ (heavily cached) |
BFCM Scaling: Pre-provision 150-200% of predicted peak. Auto-scale additional cells if metrics breach thresholds. Max cells: 2,000+ during peak.
Layer 3: Load Shedding & Prioritization
Principle: When the system is overloaded, shed low-priority traffic to protect high-priority flows.
Priority Map
Data Architecture: Event Sourcing and Consistency Models
Event Sourcing: The Foundation of Auditability
Principle: Every state change is an event. Replay events to rebuild state.
Why Event Sourcing for Orders
Traditional Approach (CRUD): Update orders table → update inventory → update user. If any fails → rollback (complex).
Event-Sourced Approach: Emit OrderCreated event to Kafka → Order Service consumes → Inventory Service consumes → Analytics Service consumes. If any fails → retry from Kafka (idempotent).
Benefits
- • Audit Trail: Complete history of every order
- • Replay Capability: Rebuild order views after bugs
- • Decoupling: Services consume events independently
- • Scalability: Kafka handles millions of events/sec
Consistency Models: When Strong, When Eventual
Consistency Model Selection
| Use Case | Consistency Model | Why |
|---|---|---|
| Inventory deduct operations | Strong | Zero oversells required |
| Payment processing | Strong | Financial accuracy critical |
| Product catalog | Eventual | Can be slightly stale |
| "Only X left" badges | Eventual | Acceptable staleness |
Caching Strategy: 5-Tier Cache Hierarchy
Cache Tiers
Tier 1: In-Process Cache (L1)
Technology: Caffeine/Guava. Size: 16-64 GB per node. TTL: 5-30 seconds. Use: User sessions, feature flags.
Tier 2: Distributed Cache (L2)
Technology: Redis Enterprise Cluster. Size: 50-200 TB globally. TTL: 30-300 seconds. Use: Product catalog, pricing.
Tier 3: CDN Edge Cache (L3)
Technology: Cloudflare/Fastly/Akamai. Size: Petabytes. TTL: 10-60 seconds. Use: Static assets, product pages.
Tier 4: Database Cache (L4)
Technology: DynamoDB DAX, Redis for PostgreSQL. TTL: 1-5 seconds. Use: Hot database queries.
Tier 5: Database (L5)
Source of truth. Use: All writes, cache misses, strong consistency reads.
Real-Time Features at Scale: WebSockets and Live Updates
The Challenge: Millions of Concurrent Connections
Requirements: 80-120 million concurrent WebSocket/SSE connections globally, sub-100ms latency for inventory updates, graceful degradation when overloaded.
WebSocket Fleet Architecture
🏗️ Architecture Flow
- Kafka Topic: inventory-events (partitioned by SKU)
- WebSocket Fleet (1,000-5,000 nodes) - Each node owns subset of SKUs
- Each node maintains 10k-50k WebSocket connections
- Client Browsers subscribe only to SKUs in cart/viewport
- Fallback: WebSocket → SSE → Long-poll → Manual refresh
Client-Side Design: Smart Subscriptions
Principle: Clients only subscribe to SKUs they care about.
- • Subscribe to SKUs in cart on WebSocket open
- • Use Intersection Observer for viewport SKUs (subscribe when visible, unsubscribe when hidden)
- • Handle WebSocket errors with fallback to SSE or polling
- • Update UI immediately when inventory changes received
Autoscaling and Capacity Management: Beyond Default Settings
Why Traditional Autoscaling Fails BFCM
Standard HPA + Cluster Autoscaler Problems: Reaction time of 2-20 minutes, flash sales can spike 100-500× within 1-2 minutes, metrics lag behind actual load, default policies are too cautious.
Predictive Autoscaling: Pre-Warming Capacity
Principle: Use historical data and known schedules to scale before traffic arrives.
📅 BFCM Pre-Warming Schedule
- • 6 AM: Pre-warm for morning traffic (500 cells)
- • 8 AM: Pre-warm for peak morning rush (1,000 cells)
- • 10 AM: Pre-warm for flash sale #1 (1,500 cells)
- • 12 PM: Pre-warm for lunch rush (1,200 cells)
- • 2 PM: Pre-warm for flash sale #2 (1,800 cells)
- • 6 PM: Pre-warm for evening peak (2,000 cells)
Reactive Autoscaling: Fast-Reacting Metrics
Principle: Use leading indicators, not lagging ones.
Custom Metrics (Leading Indicators)
Chaos Engineering: Breaking It Before Customers Do
The Problem: Regular load tests only prove you can survive what you already know. Black Friday kills you with what you don't know: partial outages, network partitions, hot shards, back-pressure cascades, and third-party black holes.
⚠️ The Golden Rule
"Never run a chaos experiment on Black Friday that you haven't already run successfully on a random Tuesday at 3 PM with 100% real traffic." If your chaos program cannot run daily in production with zero customer impact, you are not ready for Black Friday.
The 10 Critical Chaos Experiments
1. Region Evacuation
Kill an entire AWS/GCP region. Verify failover within 2 minutes, zero data loss.
2. Inventory Hot Shard Kill
Kill 1-3 ScyllaDB/Redis nodes owning top 100 SKUs. Verify automatic failover, zero oversells.
3. Database Primary Failure
Force failover Aurora/CockroachDB primary. Verify failover time < 30 seconds.
4. Kafka Broker Loss
Kill 3-5 brokers + partition leaders. Verify partition leaders re-elected within 30 seconds.
5. CDN PoP Blackhole
Block traffic to top 10 CDN PoPs. Verify traffic routes to other PoPs, latency increase < 50ms.
Observability: Building War Room Dashboards
Modern Stack: OpenTelemetry everywhere (traces, metrics, logs) → backend (Honeycomb, Lightstep, Tempo), Prometheus per cluster + Thanos/Cortex for global view, Grafana for dashboards, central log pipeline (Loki, Elasticsearch, Datadog) for fast incident triage.
Critical SLI/SLO Examples
Per-Service SLIs
| Service | SLI | Threshold |
|---|---|---|
| Inventory Service | P99 latency | < 50ms |
| Cart Service | HTTP 5xx rate | < 0.5% |
| Kafka Pipeline | Consumer lag | < 10 seconds |
| WebSocket Fleet | Connection success rate | > 99.9% |
Multi-Region Strategy: Failover and Disaster Recovery
Active-Active Architecture: Multiple regions serving traffic simultaneously. Requires global session replication, multi-region databases, and eventual consistency for some data. Benefits include lower latency, higher availability, and better capacity distribution.
🌍 Failover Success Criteria
- • Failover time < 2 minutes
- • Zero data loss
- • SLOs maintained in remaining regions
- • No user-visible errors (transparent failover)
The BFCM Runbook: Timeline and Checklists
8-12 Weeks Before BFCM
Objectives
- • Lock SLOs, error budgets, and success criteria
- • Finalize traffic forecasts with product & marketing
- • Design / update cells and routing strategy
- • Plan Game Days and scale tests
6 Weeks Before BFCM
Key Tasks
- • Run first BFCM-scale test (150% of forecast)
- • Fix bottlenecks (database indexes, N+1 queries, GC issues)
- • Implement / verify critical systems (inventory CAS, reservations, rate limiting)
1 Week Before BFCM
Final Preparations
- • Change freeze for critical components
- • Pre-warm capacity (150% of normal)
- • War room dry run (on-call roster, escalation paths, communication channels)
Post-BFCM: Learning and Continuous Improvement
Event-Sourced Orders & Inventory: Because all inventory and order changes went through Kafka, you can rebuild state after BFCM. Use replay capability for oversell detection, analytics, bug fixes, and audit trails.
📊 Key Analysis Questions
- • When did SLOs get closest to burning?
- • Where did autoscaling lag behind reality?
- • Which features were toggled off most often?
- • What broke that we didn't expect?
Conclusion
Black Friday and Cyber Monday represent the ultimate test of Site Reliability Engineering. The platforms that survive—and thrive—during BFCM are those that:
1. Design for failure at every layer (edge, app, data, region)
2. Treat inventory as sacred (strongly consistent where it matters, aggressively defensive under load)
3. Prefer isolation over heroism (cells, per-SKU limits, waiting rooms)
4. Rehearse before game day (scale tests, chaos drills, war-room dry runs)
5. Let SLOs make the hard calls (load shedding, feature kill switches, capacity decisions tied to error budgets)
Ready to Build BFCM-Ready Retail Systems?
The organizations that succeed are those that treat BFCM preparation as a year-round discipline, not a November panic. They invest in architecture, testing, and operational excellence continuously, so that when Black Friday arrives, the platform simply works.
The best system is the one that survives Black Friday without overselling, without downtime, and without losing customer trust. Sometimes that's a simple architecture with aggressive caching. Sometimes it's a complex multi-region, cell-based system with event sourcing. The choice is yours - but now you have the knowledge to make it wisely.